

Por Heron Brito — Audaz Tecnologia
O contexto
Cliente do setor de serviços para condomínios. Operação corporativa sustentada em Active Directory: autenticação, governança de acesso, aplicação de políticas, ERP Alterdata como sistema central de gestão. Ambiente Windows tradicional, múltiplos Domain Controllers — o tipo de infraestrutura que sustenta milhares de empresas brasileiras hoje.
Essa semana, durante uma operação de manutenção considerada rotineira — promoção de um novo Domain Controller — algo silencioso aconteceu. Por muitos dias, a empresa operou em estado degradado, com políticas de TI desaplicadas em toda a base de estações. Sem alerta crítico. Sem tela vermelha. Sem nada que parasse o negócio de cara.
O risco que não acende vermelho
Plano de continuidade geralmente é desenhado pra cenários binários: o sistema está no ar ou fora do ar. Mas existe uma classe de incidente que escapa desse modelo: a degradação silenciosa. Sistema responde. Usuário loga. Aparentemente, tudo certo. Mas uma camada de governança — invisível pro usuário final — parou de funcionar. Políticas de segurança não estão sendo aplicadas. Restrições de software caíram. Configurações padronizadas viraram caos individual.

Foi exatamente o que aconteceu. Um detalhe técnico durante a promoção do novo DC fez com que o subsistema responsável por replicar as políticas começasse a propagar conteúdo vazio como se fosse a versão correta. Em horas, todos os controladores estavam “saudáveis” do ponto de vista de monitoramento básico, operando sem a base de governança que sustentava o ambiente.
Por que isso importa pra um CTO
Superfície de risco invisível. Toda empresa que depende de AD pra governança tem essa exposição. Enquanto o monitoramento olhar só pra “o serviço respondeu?”, esse tipo de incidente continua passando.
O custo real é maior que o tempo de indisponibilidade. Muitos dias com políticas desaplicadas significam restrições de software desligadas, políticas de auditoria sem efeito, janela aberta pra movimentação lateral, compliance descumprido sem registro. Pra empresa em mercado regulado, isso é exposição material.
Recuperação correta de AD não é tutorial de internet. Boa parte do material disponível ensina procedimento errado pra ambiente moderno, e aplicar errado piora o cenário — pode virar crise de semanas, não de dias. Empresa que opera AD em produção precisa ter, internamente ou via parceiro, quem conhece o subsistema em profundidade.
Como recuperamos
A operação seguiu três fases, com forte uso de IA e automação nas fases de planejamento e validação:
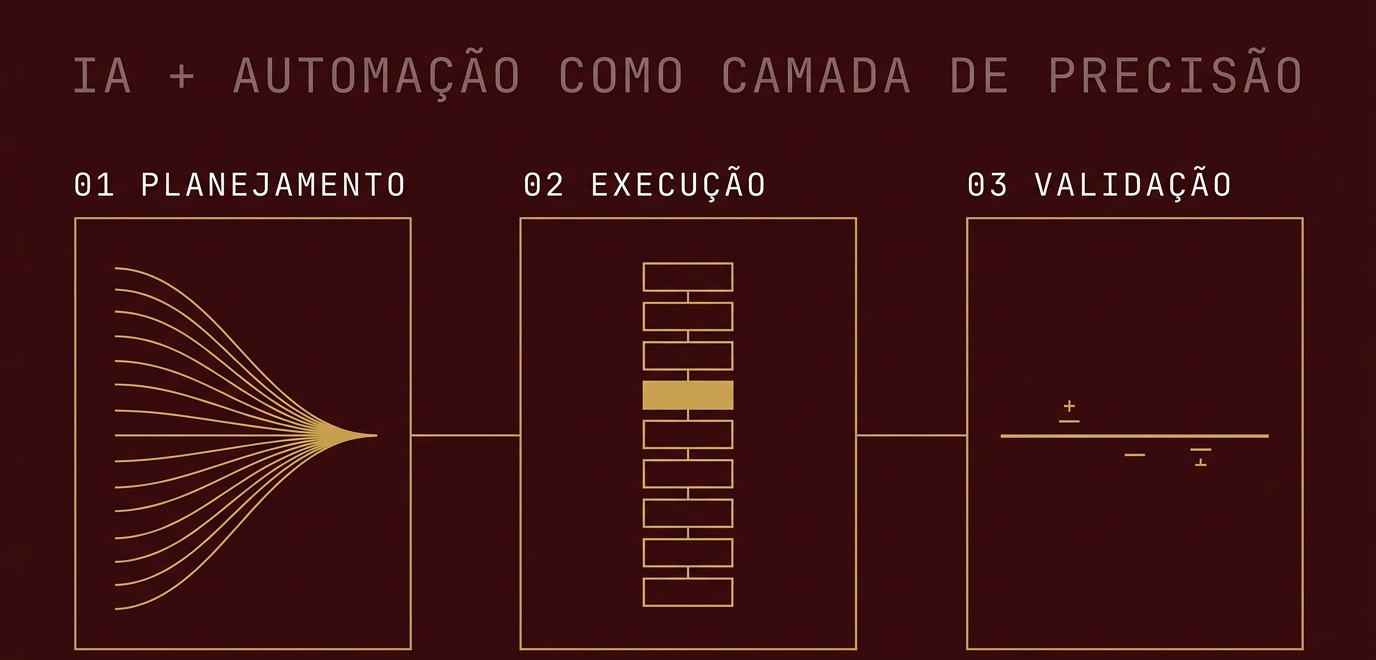
1. Diagnóstico estruturado. Antes de tocar em qualquer DC, mapeamos o estado real do ambiente via automação. IA entrou pra correlacionar eventos em volume, isolar a sequência real do incidente e ranquear hipóteses. Em vez de varrer log na mão, conseguimos reconstrução cronológica em minutos.
2. Restauração cirúrgica. Restore autoritativo do conteúdo de governança a partir do controlador íntegro, orquestrado via PowerShell pra eliminar erro humano em operação de alto impacto. Scripts revisados com apoio de IA antes de rodar em produção — busca por edge cases e riscos que escapariam de revisão humana sob pressão.
3. Validação ponta a ponta. Conferência de que toda a base de estações voltou a aplicar as políticas corretamente. IA usada novamente pra comparar comportamento pós-restore com baseline esperado e identificar qualquer divergência sutil.
O hardening que veio depois
Recuperar é metade do trabalho. Garantir que não acontece de novo é a outra metade:
- Procedimento padronizado e automatizado pra promoção de DC, com validação via PowerShell antes e depois de cada operação
- Monitoramento ativo com Zabbix em subsistemas críticos pra detectar inconsistência antes que se propague
- Visibilidade de segurança com Wazuh client nos DCs — Zabbix te avisa que algo quebrou, Wazuh te diz o que mudou e quem mudou
- Backup com retenção compatível com janela de descoberta tardia
- Validação contínua com apoio de IA comparando comportamento atual com baseline — pega o “monitoramento tá verde, mas tem algo estranho” que escapa de threshold tradicional
- Segregação de função pra operações críticas, com janela formal e aprovação
A leitura estratégica
Tem uma frase que eu repito bastante: todo software vai ser reescrito. O próprio Active Directory, do jeito que a gente conhece, não vai existir pra sempre. Identidade corporativa já tá migrando pra modelos cloud-first (Entra ID, IdPs federados, Zero Trust).
Mas enquanto a reescrita não chega, a operação atual depende da infraestrutura atual. AD, GPO, replicação — essa camada sustenta o negócio hoje. E geralmente é tratada como “o que sempre funcionou”, até o dia que para de funcionar.
Pergunte pra sua equipe esta semana
- Sabemos identificar degradação silenciosa, ou só capturamos indisponibilidade total?
- Temos backup íntegro, validado e com retenção adequada dos DCs?
- Existe runbook documentado e testado pra recuperação de AD?
- Quem domina o procedimento correto pra ambiente moderno?
Se a resposta pra alguma é “acho que sim” ou “nunca testamos de verdade”, você tem risco material exposto.
Sobre a Audaz
Atuamos como parceiro técnico de profundidade em ambientes críticos: DevOps, segurança, Cloud Native (Kubernetes), MicroSaaS sob medida e APIs cirúrgicas. Trabalhamos com CTOs e Heads de Infraestrutura que precisam reduzir risco técnico e ter previsibilidade em ambientes de missão crítica.
Se faz sentido conversar sobre o estado atual da sua infraestrutura de identidade, vamos marcar uma reunião de diagnóstico.